In ihrer Ausgabe vom 16. November 2021 berichtete die Redaktion der Zeitschrift Neerlandistiek über das aktuellste Release des umfangreichen Corpus Hedendaags Nederlands, CHN (» zum Artikel) . Das Textkorpus des Instituut voor de Nederlandse Taal (INT) wurde erneut erweitert. Es umfasst nun mehr als 2,5 Millionen Texte in niederländischer Sprache aus Büchern, Blogs, Zeitungen, Zeitschriften sowie Nachrichtensendungen und damit insgesamt rund eine Milliarde Wörter. In geografischer Hinsicht werden die Niederlande, Flandern, Surinam und die Niederländischen Antillen abgedeckt.
Wer an einer Hochschule oder einem Forschungsinstitut tätig ist, kann sich über die CLARIN-Infrastruktur in der Regel einfach und kostenfrei mit dem persönlichen Account der eigenen Einrichtung einloggen und dann direkt auf das CHN zugreifen:
In diesem Zusammenhang möchten wir zusätzlich auf einen Service unserer Kolleg:innen vom Fachinformationsdienst Linguistik hinweisen, die eine große Anzahl lizenzpflichtiger Textkorpora der European Language Resources Association (ELRA) im Angebot haben. Der Service „Korpus-Lizenzen“ richtet sich an Angehörige (Professor:innen, Dozent:innen, wissenschaftliche Mitarbeiter:innen) einer Universität oder außeruniversitären Forschungseinrichtung innerhalb Deutschlands. Voraussetzung für die Nutzung der Korpus-Lizenzen ist darüber hinaus, dass das ausgelieferte Korpus für die Untersuchung einer linguistisch relevanten Forschungsfrage eingesetzt und ausschließlich für Forschungszwecke verwendet wird.
Für Untersuchungen, die sich auf den niederländischen Sprachraum beziehen, sind unter Umständen die nachfolgenden Korpora von Interesse:
- Dutch PAROLE Distributable Corpus (ELRA-W0019): „This Dutch corpus is a 3 million words selection built according to the specifications of the PAROLE project. Over 250,000 words of corpus texts (with TEI markup suppressed) have been PoS-tagged automatically. A total of 59,798 running words has been manually corrected and checked.“ Das Dutch PAROLE-Korpus ist Teil des CHN, also auch auf diesem Weg recherchierbar.
- MLCC Multilingual and Parallel Corpora (ELRA-W0023): „The first set contains articles from 6 European newspapers: Het Financieele Dagblad (Dutch, 8.5 million words), The Financial Times (English, 30 million words), Le Monde (French, 10 million words), Handelsblatt (German, 33 million words), Il sole 24 Ore (Italian, 1.88 million words), Expansion (Spanish, 10 million words). The second set consists of a parallel corpus of translated data in the nine European official languages (1992-1994) divided into 2 sub-corpora: written questions (10.2 million words) and parliamentary debates (5 to 8 million words per language).“ Bei der in den MLCC Multilingual and Parallel Corpora enthaltenen Zeitung Het Financieele Dagblad handelt es sich um die Jahrgänge 1992-1993. Die MLCC-Parallelkorpora beruhen auf Daten des Übersetzungsdienstes der EU-Kommission.
- 2006 CoNLL Shared Task – Ten Languages (ELRA-W0086): „2006 CoNLL Shared Task – Ten Languages consists of dependency treebanks in ten languages used as part of the CoNLL 2006 shared task on multi-lingual dependency parsing. The languages covered in this release are: Bulgarian, Danish, Dutch, German, Japanese, Portuguese, Slovene, Spanish, Swedish and Turkish.“
- ECI/MCI (European Corpus Initiative/Multilingual Corpus I) (ELRA-W0004): „Over 98 million words, covering most of the major Euopean languages, as well as Turkish, Japanese, Russian, Chinese, Malay and more.“ Anteil niederländischsprachiger Daten: „Extracts from the Leiden Corpus of Dutch, consisting of newspapers, transcribed speech, etc. Provided by Institut voor Nederlandse Lexicologie, Leiden, Holland. Approximately 5.5 million words.“
» zu den Korpus-Lizenzen des FID Linguistik
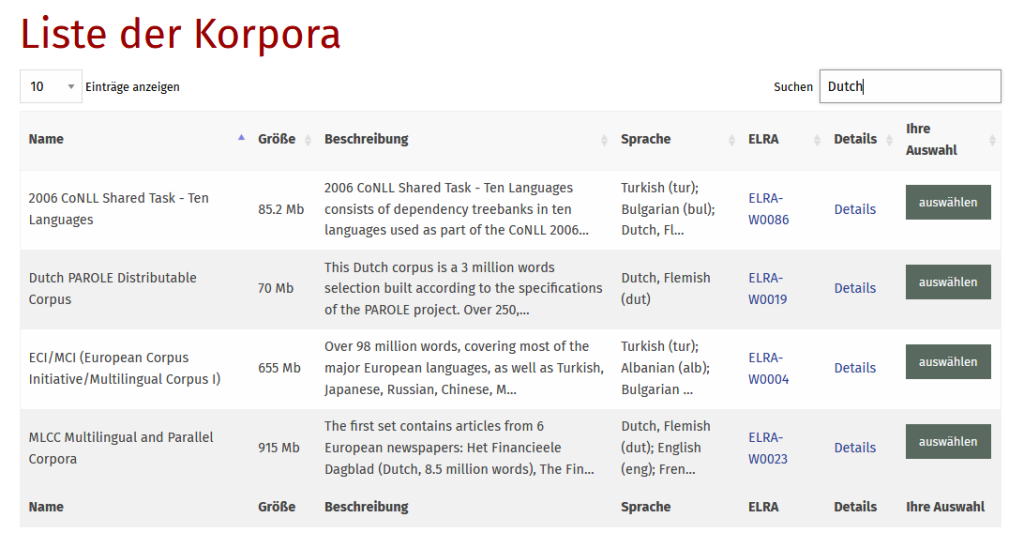
niederländische Textkorpora im Angebot des FID Linguistik, Bildnachweis: FID Linguistik